
(Cinnamon twig decoction) contains Cinammon Twigs (桂枝), Peony Root (白芍), Ginger (生姜), Red Jujubes (红枣) and Liquorice root (甘草).
How to use DocuSky’s Post-Search Classification function to reveal historical change
This blog describes how to analyse the text corpuses in the Polyglot Asian Medicine website, a site which provides tools for researching the history of Asian medicines. In particular it will show how to track a specific term cluster, in this case a classical drug recipe, across multiple genres and time periods, and identify related terms where they occur. It uses the example of a classic formula from the earliest work of theoretical pharmacology, the Shanghan lun 傷寒論, by Zhang Ji 張機 in the late second century, and shows how to trace its transformation by later physicians over time.
This application of the Polyglot data and DocuSky tools is the product of multiple contributors. Tracking a specific recipe to show its historical variations, demonstrates a method presented by Joachim Prackwieser in ICHSTEAM Frankfurt, 2023. See Prackwieser, forthcoming in East Asian Science Technology and Medicine. Technical demonstration presented by Stanley-Baker and Prackwieser in DADH Tainan 2023. 桂枝湯 data-subset and user-experience development by 洪一梅 and 黃嘉宏 within the DocuSky team. Termlist of Chinese drug terms produced from back-end data from the Polyglot Medicine: Knowledge Graph.
In this exercise, we will analyse a subset database of all instances of the recipe Cinnamon Twig Decoction (Guizhi tang GZT) that have been tagged in the database. GZT is commonly used in treatments today to release exterior wind-cold trapped in the muscles. It consists of five main ingredients as the base recipe, which, over time, different physicians have adapted in different ways, adding or subtracting (加减) different ingredients to suit their patients, or using the recipe for different applications. Tracking their variation allows us to see commonalities and differences between physicians’ approaches, and how physicians’ praxis was shaped by larger patterns in the history of Chinese medicine.
The DrugsAcrossAsia_China database contains hundreds of Chinese medical texts, which have been carefully segmented into chapters, sections of those chapters, and paragraphs. Each section is annotated with detailed bibliographic data (metadata) about the source text, including the original date, author, medical genre and the woodblock or manuscript edition. The texts have been densely tagged for specific phrase types, including recipe titles, recipe ingredients, disease syndromes and many others. For this exercise, a small subset database has been extracted containing all paragraphs where the recipe name GZT 桂枝汤 has been tagged as a recipe 方剂.

DocuSky allows one to search for massive term sets across the corpus, and then parse those results according to this metadata. This allows one to organise the search results, and sift between individual passages, as well as get a large-scale overview of the results. This is called POST-SEARCH CLASSIFICATION, and this is the key tool demonstrated here.
In this exercise, you will analyse a bespoke file that contains all the paragraphs containing tagged Guizhi tang recipes. You will search the file for all the drug names contained in each passage, and compare the contents of the passages to one another using a graphical interface. Through recursively comparing the graphed image and individual paragraphs, you will produce a graph that visualises the relationships between different drug recipes, that can be the foundation for novel research questions.
UPLOAD YOUR DATABASE
Download this dataset to your desktop. This file is a subset of the DrugsAcrossAsia_China database, containing only those paragraphs with the tagged recipe name 桂枝湯.

Then register with DocuSky:
Then login.
Using the same drop down menu, go to “Personal Database”

Upload your dataset into the website.
When it has loaded, return to the initial page, and under TOOLS find TEXT-MINING AND ANALSYSIS.
TERM STATISTICS ANALYSIS TOOL

Find the Tag/Term Statistics Tool, and click ENTER.
This tool will allow you to :
1) load the dataset into memory from your online CORPUS
2) load a massive TERMLIST into memory,
3) ANALYSE the corpus for your terms,
4) then output the RESULT as an excel file.
1) in CORPUS, use the DocuSky Corpus Widget to load your dataset.
a) click on 載入 to load into memory.
2) TERMLIST: Download this termlist to your desktop.
a) Use Method 1 to upload the file from your desktop.
3) ANALYSIS: Run Analysis,
4) RESULT: This outputs three types of search result
a) Basic Term Frequencies : the occurrences of each term as TF – the total frequency of terms, and DF or document frequency – the total documents in database which contain the term.
b) Categorized File Result: frequency and variety of all terms which appear in each paragraph.
c) Categorized Term Result: frequency of individual terms per paragraph.

b) and c) allow you to select which metadata to export with the results and download with your term search results.
Select b) Categorized File Result, and tick the following metadata:
PassageId
Author
Source
TimeSeqnotAfter

Then save to your desktop
PREPARING THE DATA
Note, if the following section on Excel doesn’t work for you, click here to download an already prepared file.

Open the file in excel.
Click View > Freeze Top Row

Select Top Row
Click Home > Sort & Filter > Filter

Right click at top of Column D.
Insert a new column, title it “Link”
In Cell D2, insert the following code.
="https://docusky.org.tw/DocuSky/webApi/webpage-open-3in1.php?ownerUsername=open&db=guizhitang&corpus=DrugsAcrossAsia_China&queryBase=&queryNarrowDown=%7B"&C2&"%7D&spType=search&snippets=off&submit=%E7%B8%AE%E5%B0%8F%E7%AF%84%E5%9C%8D" Fill Column D with the code, by dragging the cell handle, or pasting CTRL+F.
These links will take you to link to the individual passages on the row, allowing you to move between the macro scale table and individual passages. This allows you to recursively prune your results through data analysis and close reading.
Click on the filter on Column E and de-seleect “MetaTags:*:o”

Select Columns D, F, G, H, I, and L.
Copy and paste these into a new worksheet, using CTRL+C and CTRL+V.
Select the entire data field from B1:F109 and press CTRL+C.
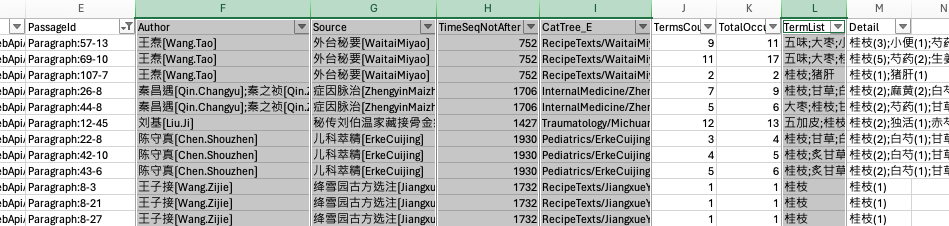
Again, if this section didn’t work for you, you can download a pre-filtered file here.
GRAPHING THE DATA IN PALLADIO
Open Palladio here: https://hdlab.stanford.edu/palladio-app/#/upload
Paste the data into the field by clicking in the open field and pressing CTRL+V. See image below.
Click “Load” to upload it into Palladio.

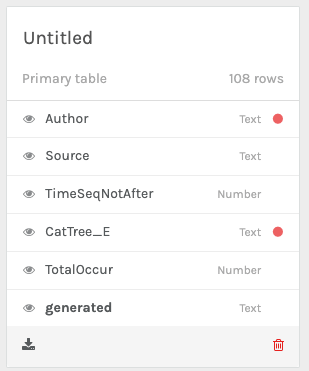
Click on Author and click on the semi-colon under “Verify special characters”. Click Done to confirm..
In TimeSeqnotAfter and change “Data Type” to Date.
In CatTree_E and click on the symbols under “Verify special characters”.
In TermList type a semi-colon “;” into “Multiple values.”
This last action tells Palladio that the semi-colon indicates that individual data cells contain multiple distinct data points, separated by “;”. It will change the display

Now select GRAPH in the menu above.
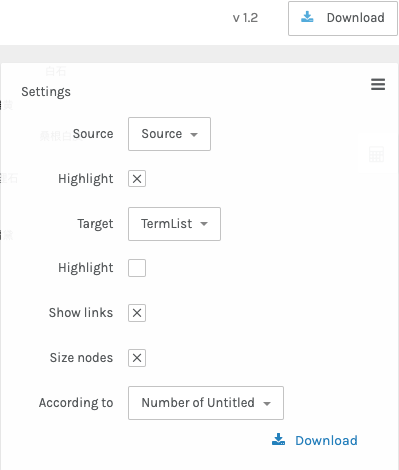
Select the “Hamburger” and input the following:
Source: Source
Highlight Source
Target: TermList
Show links
Size nodes
Click “Hamburger” again to make it disappear.

EXPLORING THE GRAPH




At the top of the TermList column, select the Tickbox icon.
This highlights the items in the lists, allowing you to clear items from the graph.
Do the same for the Source column.
You can now recursively explore the graph. You can pull the nodes around the page, and place them where you need to see more clearly. Other nodes adjust accordingly.
RECURSIVE EXPLORATION BETWEEN GRAPH AND TEXT
Currently, the graph has a lot noise, and needs cleaning and exploring to find patterns.
Here the analytical questions, the data revealed, and the source texts come into relationship. This process involves recursive questioning of the similarities and patterns that become visible as you manipulate and tease out your data.
FILTERING FOR CHANGE
Because we want to trace variations of the GZT recipe, drugs that have been introduced in combination to the recipe, this means that the stable ingredients of GZT, which don’t change, are not a critical question. We can (mainly) assume that all recipes will contain those main ingredients. Thus these constitute noise. So we can clear those out.
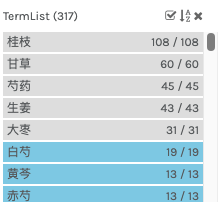
Cancel the five main ingredients:
Cinammon Twigs (桂枝),
Peony Root (白芍),
Ginger (生姜),
Red Jujubes (红枣)
Liquorice root (甘草).
You’ll notice some large nodes which have a lot of drugs. These look suspicious. The largest is titled 幼幼新书〔YouyouXinshu〕. Let’s explore it. Copy this title from here.

Search for it in the excel file by pressing CTRL+F and pasting the title into the search bar with CTRL+V.
Find the cell from the LINK column which corresponds to the title.
Copy the link with CTRL+C, and paste it into your browser.
Alternatively, you can just click here to see the passage.
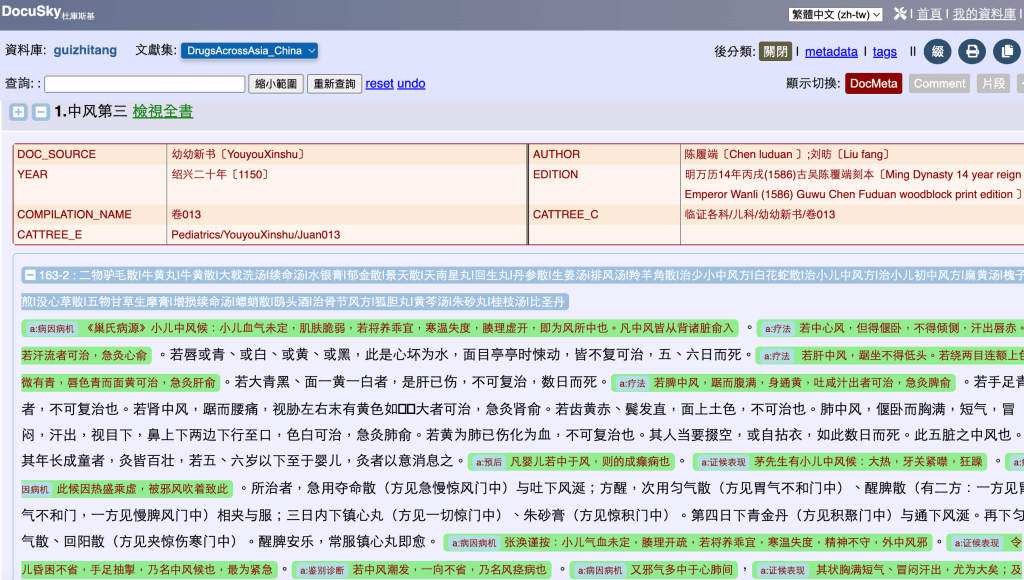
It turns out there are many recipes (方剂) tagged here. Search 方剂 in the page to highlight them. Only one is 桂枝汤. Therefore these other recipes are noise, and you should remove this passage from the graph.
Return to the Palladio window.
Search the page using CTRL+F for the recipe 幼幼新书〔YouyouXinshu〕. It will be highlighted both on the graph and in the facet.
Click CTRL+G repeatedly to foreground different instances on the page. The Facet will be highlighted.
Click on the facet to clear it from the graph.
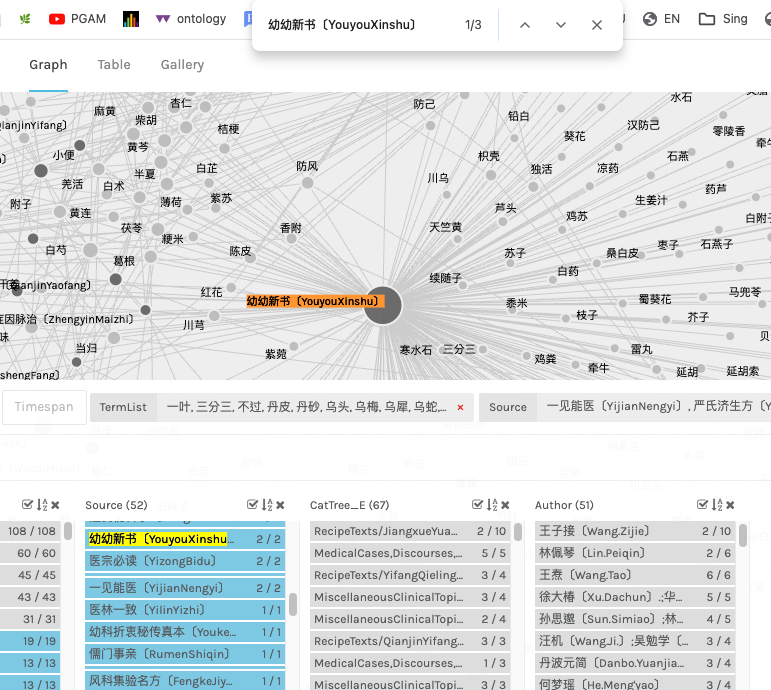
In this way, you can recursively clean the page of noise, to reveal the data you want. I suggest removing a few other texts. Don’t take my word for it, explore the passages to see for yourself:
本草汇言〔BencaoHuiyan〕
小儿推拿广意〔Xiao’erTuinaGuangyi〕
一见能医〔YijianNengyi〕 Passage 1 Passage 2
HUNTING FOR PATTERNS
Having cleared much of the noise, you can now look for patterns. Mainly this involves moving the SOURCE nodes around to compare their relationships to the drugs. Drag the sources to the periphery, leaving the drugs free in the centre. Dragging nodes over one another allows you to visually compare how similar they are to other nodes.
(TIP – if you don’t click on the drugs, they remain “free floating” and will follow the nodes they are attached to).
This process can take a long time, and also requires good knowledge of the sources and the research field. You can see one I’ve prepared earlier, by downloading this file. Upload it into Palladio here using Load an existing project.
CHANGE OVER TIME
You can also explore change over time using the TIMELINE feature which is located by the FACETs.
OVERVIEW OF GENERAL FEATURES OF THE GUIZHI TANG RECIPE ACROSS TIME
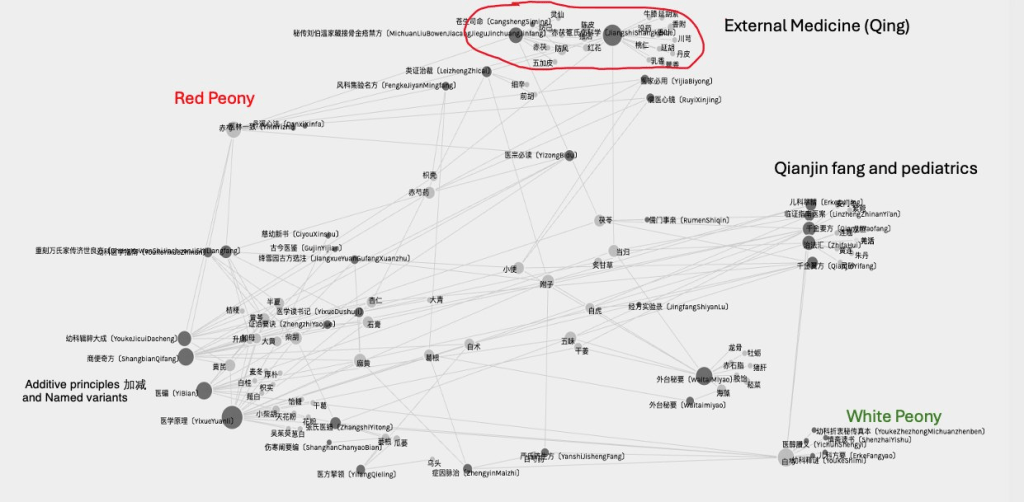
Through these means, one can establish an overview of general patterns of the recipe as above.
This raises new questions and hypotheses, which I discuss in the lecture.
The cluster in the lower left, appear very similar. Why? When were they written? Did the authors have social connections, or were they part of a school of thought?
Peony only became distinguished as white or red in the Song dynasty. What are the contours of the White Peony/Red Peony debate? Why does White Peony come back into popularity in the Ming dynasty?
Is there more to be said about the adoption of GZT for external medicine in the Ming/Qing?
The lower left group tend to use a named epistemic genre of RECIPE ADDITIONS/SUBTRACTIONS (加減方). Does this indicate a periodisation or school in which this method became popular?
In this way, data visualisation of texts, with the help of DocuSky and Palladio, enables the generation of new research questions, produced directly from patterns observed in primary sources, bypassing the influence of secondary scholarship.
CREDIT: This method draws on techniques developed by Joachim Prackwieser, forthcoming.
