The following is a simple guide to accessing and analyzing the Daozang (Daoist Canon) via DocuSky’s tool known as Tagstats, which allows you to upload your own list of vocabulary and locate it within the entire canon. (DocuSky’s English interface is forthcoming. Steps below will not require any knowledge of Chinese)
1. Using DocuSky’s Tagstats tool to generate term occurrence statistics
Start by going to DocuSky’s Tagstats tool webpage: http://docusky.org.tw/DocuSky/docuTools/TagStatsTool/

As is in workflow diagram, the process follows
a. CORPUS: start with loading a corpus, which in our case is the entire Daoist canon;
b. TERMLIST: load your personal vocabulary list, which in our case is a list of names of gods;
c. ANALYSIS: where the vocabulary you supplied is located within the corpus; and,
d. RESULT: download the results for use in other analytical tools
a. CORPUS: start with loading a corpus, which in our case is the entire Daoist canon
Click on “CORPUS”, and then on “DocuSky Corpus Widget” under “Method 2: Add from DocuSky”
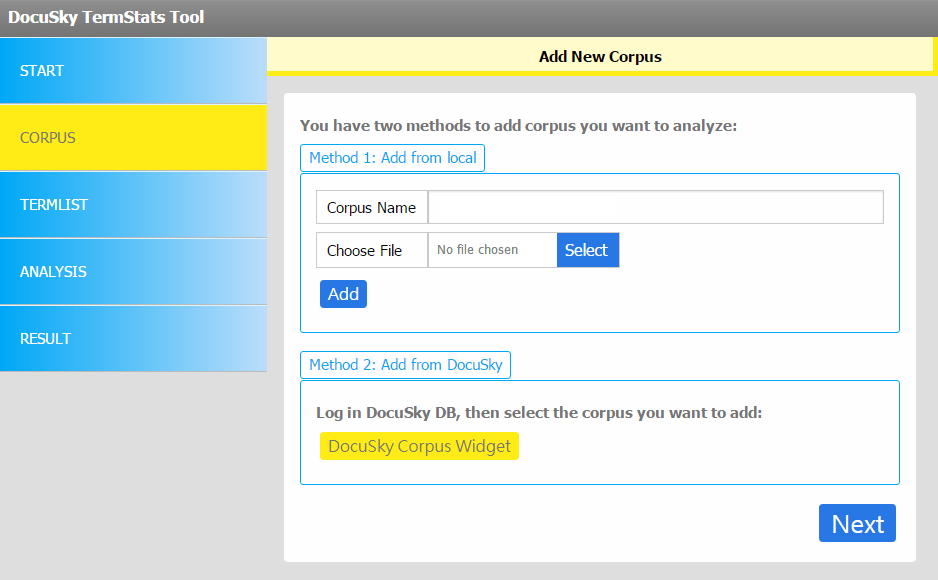
Enter the credentials of “msb@ntu.edu.sg” for “Username” and “Daoi$t” for “Password”. Then hit “登入” (login).
This shows you the corpus in this account. Click on “載入” (load) with the corpus titled “FullDZ_WithMetadata”. Please have some patience while it loads, as there are about 1500 texts split into 5500 juans.

When the loading is completed you should see your loaded corpus under the Corpus List in the right-hand column.

b. TERMLIST: load your personal vocabulary list, which in our case is a list of names of gods
While you are waiting for the corpus to load, you can upload your vocabulary list. This could be critical vocabulary related to any particular genre that interests you. If you click on “TERMLIST” it will bring you here. Click on “Select” next to “Choose Files” under “Method 1: Add from local”.
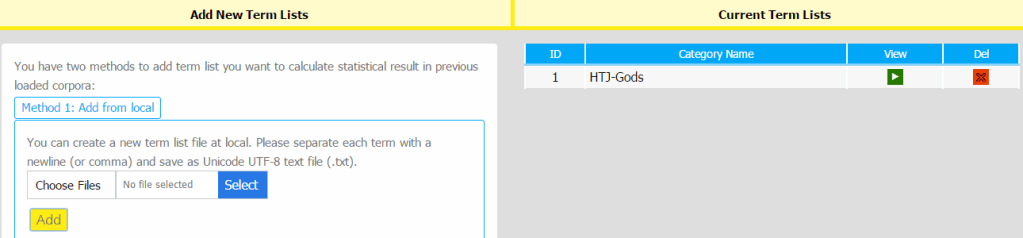
In case you do not have a vocabulary list to upload, here is one which is a list of the names of Daoist gods. After you click “Add” you should see the vocabulary list appear on the right hand column under “Current Term Lists”.
c. ANALYSIS: where the vocabulary you supplied is located within the corpus
Click on “ANALYSIS” and check that the corpus and term list listed are correct. Then click “Run Analysis” at the bottom of the page.

Wait till it is complete. Again, please have some patience.

d. RESULT: download the results for use in other analytical tools
Click on “RESULT”. There are multiple formats to download the analytical output here. Do download them to get a sense of what is contained in which, and how you might be able to use them.
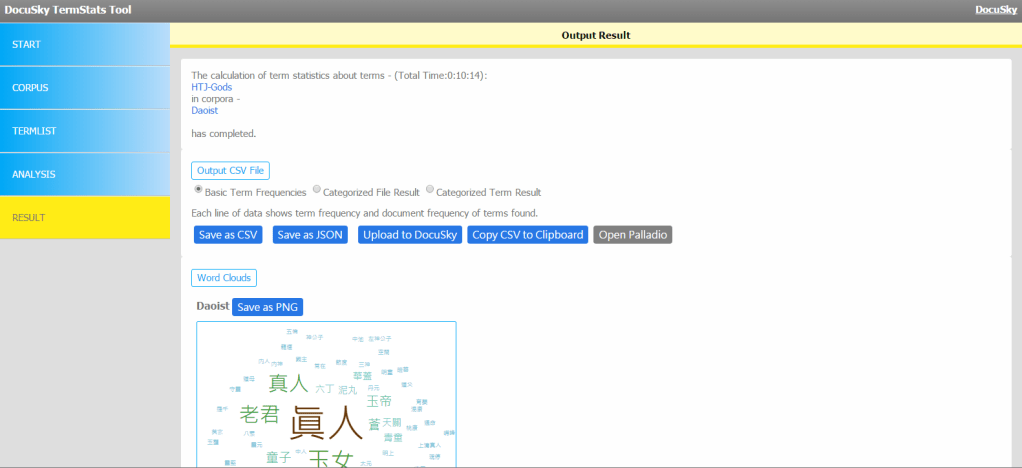
In our case, select “Categorized File Result”, choose all the metadata columns to output, and click “Save as CSV” to download it.
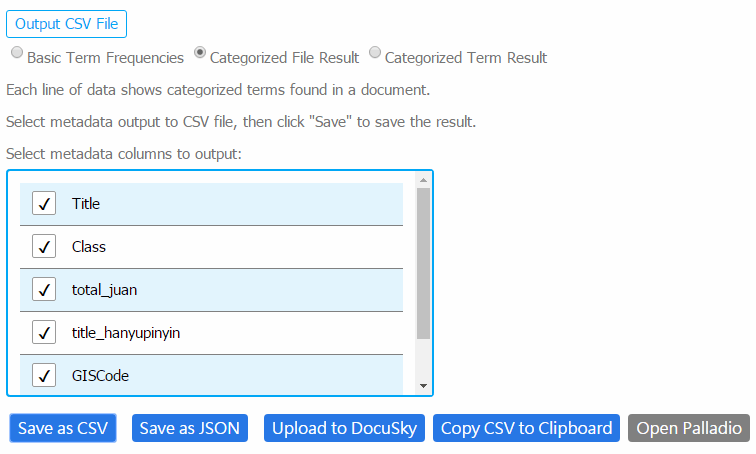
The CSV, when opened in Excel, turns up like this. We will be attaching the Daoist Canon’s metadata so it can be employed in analysis. You can also click on “Open Palladio” on the Tagstats page which will bring you to Palladio’s data upload page.
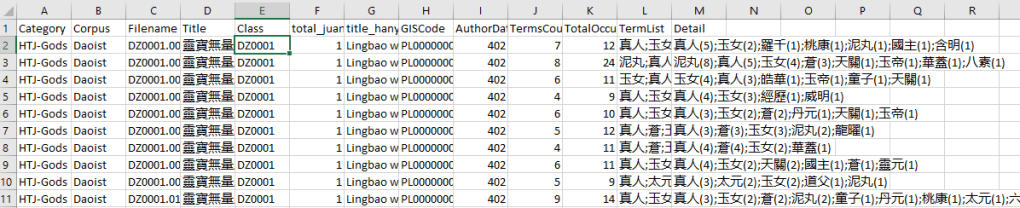
2. Using Microsoft VLOOKUP function to attach metadata to Tagstats tool’s results
Download the Daoist Canon’s metadata here: https://researchdata.ntu.edu.sg/file.xhtml?fileId=21089&version=2.0

Copy B1:X1493 (select, then Ctrl+C), and paste (shortcut: Ctrl+V) it into a new sheet on the CSV output we obtained from the Tagstats tool.
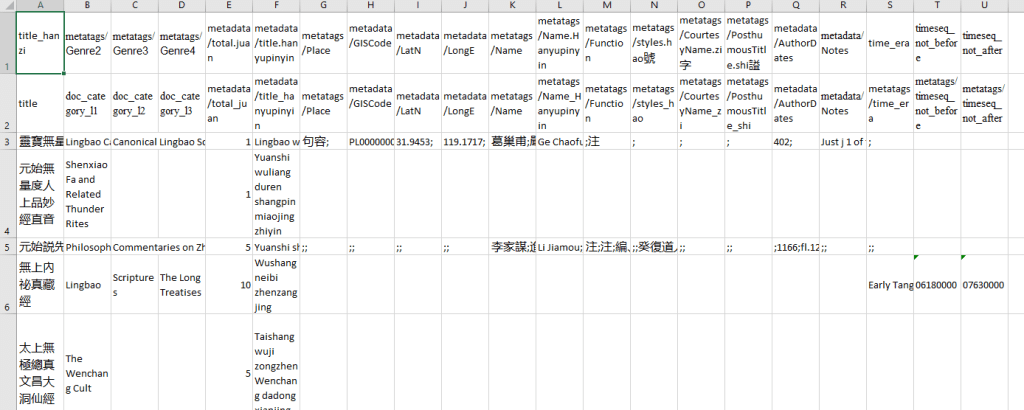
Then copy D2:W2 and paste it to the end of the first row of the CSV results, i.e. at N1. Further add a new row at the top of the CSV, and add numbers 4 to 23 above the newly pasted headers.

We will now apply a VLOOKUP function to populate the metadata to the results page. Further reading on how VLOOKUP works can be found here: https://support.office.com/en-us/article/vlookup-function-0bbc8083-26fe-4963-8ab8-93a18ad188a1
The VLOOKUP function is written in the format of “=VLOOKUP(What you want to look up, where you want to look for it, the column number in the range containing the value to return, return an Approximate or Exact match – indicated as 1/TRUE, or 0/FALSE)”.
Thus we will write “=VLOOKUP($E3,Sheet1!$A$1:$W$1493,N$1,FALSE)” at cell N3, and then copy it to the entire N3:AI4563 i.e. to fill out the entire search results from DocuSky. Then copy the entire first sheet, right click, choose “Paste Special>Values”. Then delete the first row with only the number 4 to 23. The outcome should look like this:

Save the CSV. Rename it if you would like to do so. In case you were not successful replicating the VLOOKUP function, download the new CSV with metadata here: https://www.dropbox.com/s/7p7vgs8gnww61hb/Result_CategorizedFileResult_20200413173253_WithMetadata.csv?dl=0
3. Importing into Palladio
Open Palladio here: https://hdlab.stanford.edu/palladio-app/#/upload
Copy the CSV’s content to the blank space under “Load .csv or spreadsheet”. Click “Load”.

Click on the red dot next to “Term List”. This indicates that Palladio is uncertain how the data is to be read or segmented. You may also resolve all other red dots if they are necessary for your analysis.
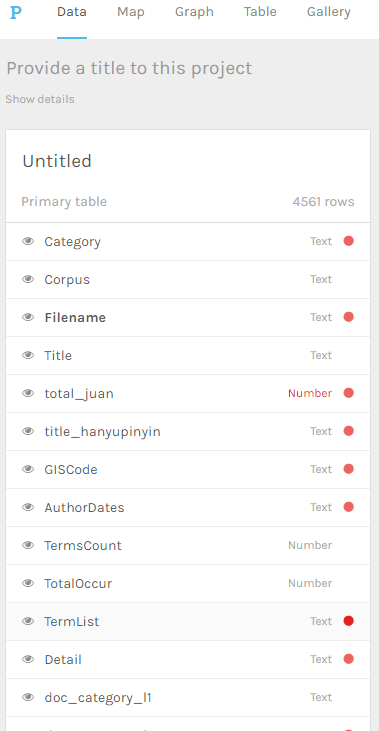
Enter a semicolon in the box below “Multiple values”. This indicates that there are multiple values in one record, and they are separated by a semicolon. Entering this will cause Palladio to split the terms following each semicolon. Click “Done”.
Click on “Graph” at the top menu bar. Select “Title” for “Source”, “Termlist” for Target. The network will be automatically generated. You can choose to highlight either the Title or Termlist, and size the nodes according to different criteria.

To further filter the visualization to make it more manageable, click on “Facet”, then “Dimensions”. Select the three “doc_category” (l1, l2, l3), which are genre-type information about the texts in the Daoist Canon, then click “Close”.

Clicking on any particular categories will act as a filter. Here we selected “Medicine and Pharmacology” in the l1 Category.

To save these results and your visualization. Click on “Download” at the top-right corner.

